.svg)
Created by: Kristinn Magnusson
In this article, you will read about the differences between Process & Object Group Failure Types with a worked example.
Groups have two failure types, which decide what happens when a subtask fails:
- Ignore Failure - This failure type will ignore the failure.
- Fail Parent - When a task with a failure type Fail Parent fails, it will prevent subsequent siblings from being executed. It will also mark its parent as failed, and depending on its failure type, it can either stop its siblings from being executed or ignore the failure of its child.
Worked Example
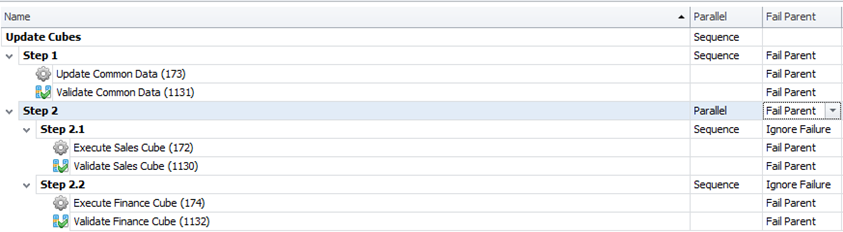
You have a process with 3 stages:
- Update Common
- Update Sales
- Update Finance
Common needs to be updated before Sales and Finance, but Sales and Finance are independent of each other.
Step 1 should then contain all tasks that concern updating the common data. Depending on how Common data is updated, this step is likely to require sequential parallelism. If updating Common fails, we want the process to stop and therefore both tasks under Update Common (Step 1) should be set to Fail Parent along with the step itself.
Since we want Sales and Finance to update only after Common has been updated, we should set the Process Group itself as sequential.
After that create a new step, Step 2.
Best practice would then be to make Step 2 parallel - failure type is irrelevant for this step as can be seen later. With this configuration, we then add sub-steps to Step 2, Step 2.1 and Step 2.2. These steps should contain all tasks concerning Sales and Finance. Like with Step 1, it depends on these tasks, if steps 2.1 and 2.2 have parallelism set to Sequential or not, but they should be set to Ignore Failure.
Further explanation of how this process will run can be shown by flow chart:
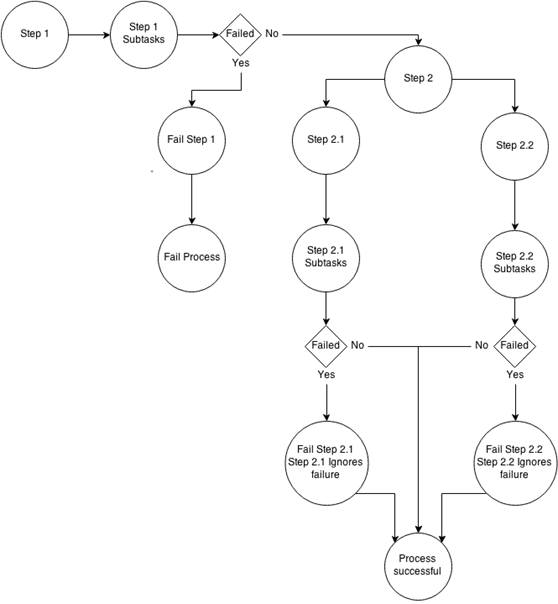
Looking through the flowchart we can see that the only way for the process to fail so that our Finance and Sales data will not be executed is by Common failing. Notice too, that even if either Sales or Finance fails, the process will be successful. This is due to Steps 2.1 and 2.2 ignoring failures.
This is the correct way to set the process up, if we had for example Step 3 (or Step 2.3), which did not depend on Sales or Finance data at all.
Step 3 would then be executed after Step 2, even if Sales or Finance failed. It would be wrong behaviour though if Step 3 depends on Sales or Finance.
Note though, even if the process is successful, the tasks that fail will use their own failure configurations, such as sending emails or showing red on process maps, irrelevant of its or its parent step's failure type inside the process group.
Kristinn is the author of this solution article.